

From Narrow AI to Self-Improving AI: Are We Getting Closer to AGI?
The Path From Narrow AI to AGI: Has GPT-4 Developed a Theory of Mind?

Chatbots are sometimes described as simple machines that can only predict the next word while others claim that they already have consciousness. To answer the question presented in the title, it is necessary to dive into the workings of LLMs (large language models), examine the capabilities of narrow AI, and determine when it can be considered AGI. Is the architecture of neural networks enough to develop AGI? I aim to provide an analysis of this question in a clear and understandable manner.
Basic arguments
One argument in favor of the statement that "ChatGPT is just a statistical program predicting the next word" is that the model is essentially a language model that has been trained on large amounts of text data using statistical methods. The model does not have any understanding of the meaning or context of the text it generates, but rather uses statistical patterns to predict the most likely word or phrase that would follow a given input. This approach is purely statistical and does not involve any form of semantic understanding or reasoning. This type of understanding requires "real intelligence" or, in AI terms, AGI. (I wrote about this topic in my previous article).
However, it is not entirely accurate to say that ChatGPT is "just" a statistical program predicting the next word. While it is true that the model uses statistical patterns to generate text, it does so in a way that goes beyond simple word prediction. The model uses a complex system of attention mechanisms, deep learning algorithms, and transformer architectures to generate text that is both fluent and coherent. The model can also generate responses that are contextually relevant and demonstrate a basic understanding of the input.
ChatGPT is capable of generating text in a wide range of styles and tones, from formal to conversational, and can even emulate the writing style of specific authors or genres. This requires the model to have a certain degree of linguistic sophistication beyond simple word prediction. But is it similar to how the human brain works? Let's take a look!
Human vs AI by numbers

The human brain and large language models such as GPT-3 both rely on complex networks of connections and parameters to process and store information. The parameters of LLMs are a good analog for comparison with human brain synapses. While the human brain contains around 86 billion neurons and 150 trillion synapses, GPT-3 has 175 billion parameters. That's almost a 1000-fold difference, which suggests that there is a lot of room for improvement. However, humans don't solely focus on thinking, as they also need other resources to maintain their bodies.
Both parameters in large language models and synapses in the human brain are critical components that allow for complex information processing and storage. Parameters in language models are analogous to synapses in the brain because they serve as the connections between different components of the network. In the brain, synapses allow neurons to communicate and exchange information while in language models parameters allow the model to learn and recognize patterns in data. Both parameters and synapses are capable of being strengthened or weakened over time through reinforcement learning or other forms of training, which helps both systems adapt to new information and improve their performance on various tasks.
In both cases, these complex networks allow for the processing of massive amounts of information, allowing for more accurate predictions and more sophisticated language understanding. Despite the differences between the physical structure of parameters and synapses, their functional similarities suggest that there may be underlying similarities in the way that language models and the human brain process and store information.
Abstraction and symbolic language
Another aspect of complex intelligence is language abstraction, and this is important because this specific type of ability is unique to humans. Language abstraction refers to the ability of humans to think and communicate using abstract concepts and ideas that do not necessarily correspond to tangible objects or experiences. This is made possible by symbolic language, which uses symbols to represent words and phrases enabling humans to communicate complex ideas and concepts. Symbolic language is what sets humans apart from other species and allows for collective learning, the sharing and preservation of knowledge over generations. This ability has been crucial to human progress and has enabled us to achieve remarkable feats, from technological advancements to artistic and intellectual creations.
Language abstraction is also an important part of LLMs. Abstraction involves the ability to extract and generalize patterns from large datasets of text which allows LLMs to understand the underlying structure and meaning of language. Symbolic language plays a major role in this process, as it allows LLMs to represent and manipulate complex concepts in a way that is computationally teachable.
One of the key advantages of symbolic language in LLMs is its ability to simplify complex ideas and make them more accessible to machine learning algorithms. By representing language in terms of abstract symbols and concepts, LLMs can more easily recognize and analyze patterns in large datasets, and generate more accurate predictions and responses to queries.
These are just patterns…
Basically, human intelligence is also based on patterns. When we create art, we do it by mimicking what we have seen before. Talented artists have their own unique style and perspective, but these are also developed based on the works of other artists.
Patterns can consist of simple features or elements, such as lines or shapes. As these features are combined and abstracted into higher-level concepts, more complex patterns emerge. For example, a pattern of letters may form a word, which in turn is part of a sentence, and so on. This type of organization is referred to as hierarchical knowledge. Hierarchical knowledge facilitates pattern recognition by providing a framework for organizing and categorizing patterns. It refers to the organization of knowledge into a hierarchical structure, with higher-level concepts built upon lower-level ones.
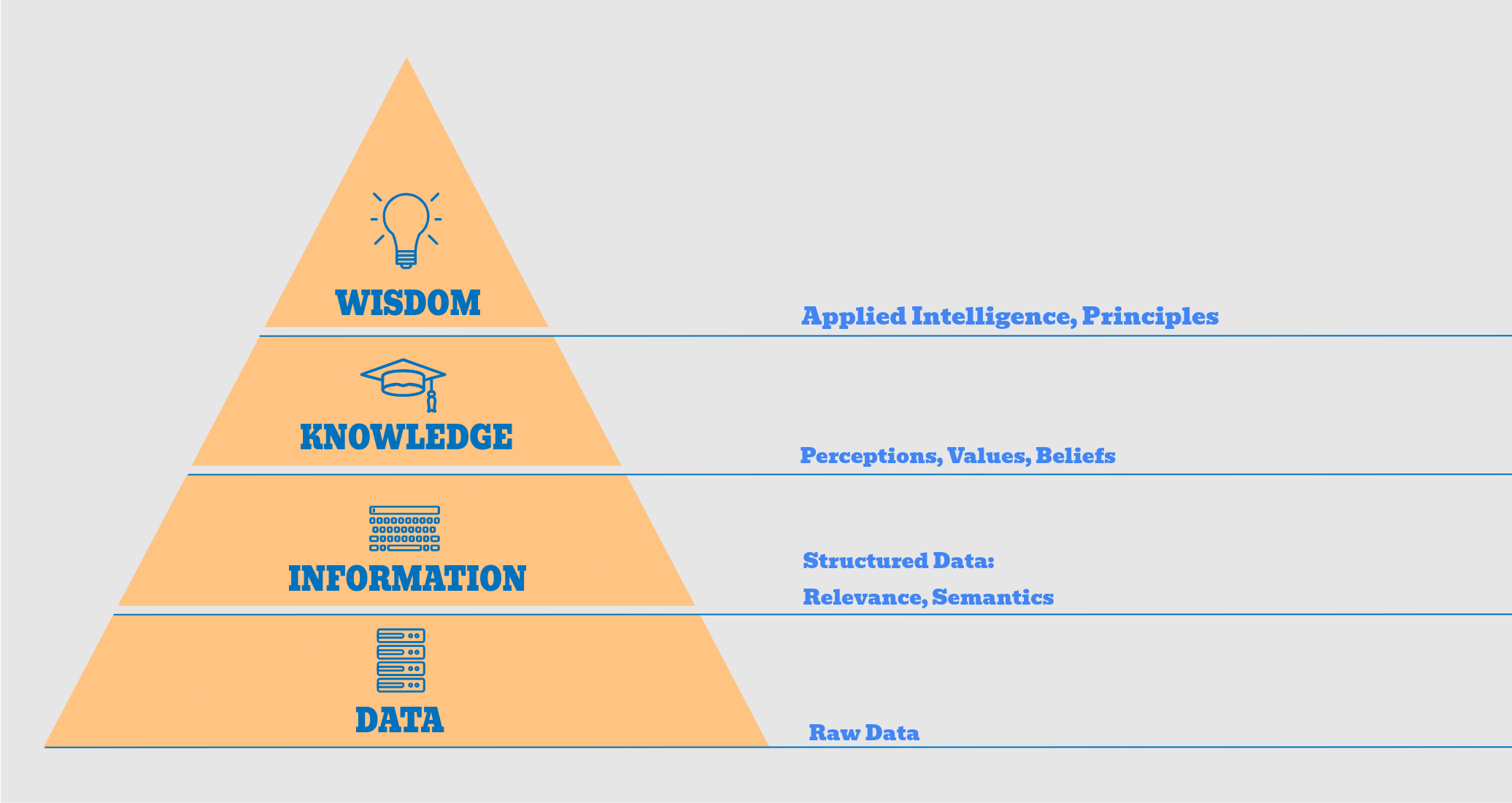
Data: Training data is a crucial component of GPT models, as it is used to teach the model how to generate coherent and relevant text. All model is trained on a corpus of text data, such as large collections of books, articles, and social media posts. This data provides the foundation for LLMs to learn patterns and relationships between words and phrases.
Information: Structured data is the result of the LLM processing and interpreting the raw data. In order to extract information from text data, GPT models use an attention mechanism, which allows the model to focus on certain parts of the input text while generating output text. This attention mechanism is a critical component of the model, as it enables the model to identify important patterns and relationships within the text.
Knowledge: The ability to apply understanding of patterns and relationships in the data to generate responses that require a deeper level of understanding, such as answering questions about specific topics or summarizing complex information. For example, an LLM trained on medical texts may be able to answer questions about diseases and their treatments. Once the model has extracted information from the text data it can use this information to generate new insights and knowledge. This is achieved by adjusting the weights of the model which are the values that determine how the model combines information from different parts of the text to generate output text. By adjusting these weights, the model can learn to generate more accurate and relevant text.
Wisdom: GPT models can be used to make wise decisions by leveraging the knowledge and experience they have gained from the training data. The ability to make wise and insightful judgments based on knowledge and experience. While LLMs may not have true wisdom, they can generate responses that appear wise or insightful. For example, an LLM may generate a response that expresses sympathy and understanding for a customer emotional state based on its analysis of their input.
Combinatorial explosion of knowledge

Combinatorial explosion refers to the exponential growth in the number of possible outcomes as the number of options or variables increases. GPT models have the ability to generate natural language text. The number of parameters in a machine learning model refers to the number of variables or weights that the model has been trained on. Each paramaters represents a specific aspect of the data that the model is trained on, and adjusting these parameters can affect the model's ability to generate accurate and high-quality text. As the number of parameters in a GPT model increases, the complexity of the model grows exponentially, leading to a massive increase in the number of possible outcomes. This makes it increasingly difficult to predict the model's output, particularly for longer input sequences. As a result, the behavior of the model can exhibit emergent abilities that are difficult to predict or explain.
Emergent abilities
Emergent abilities refer to new and unexpected capabilities that arise from complex systems like LLMs. This abilities was not specifically programmed into the algorithm, but rather emerged as a result of the algorithm's ability to learn and recognize patterns in data.
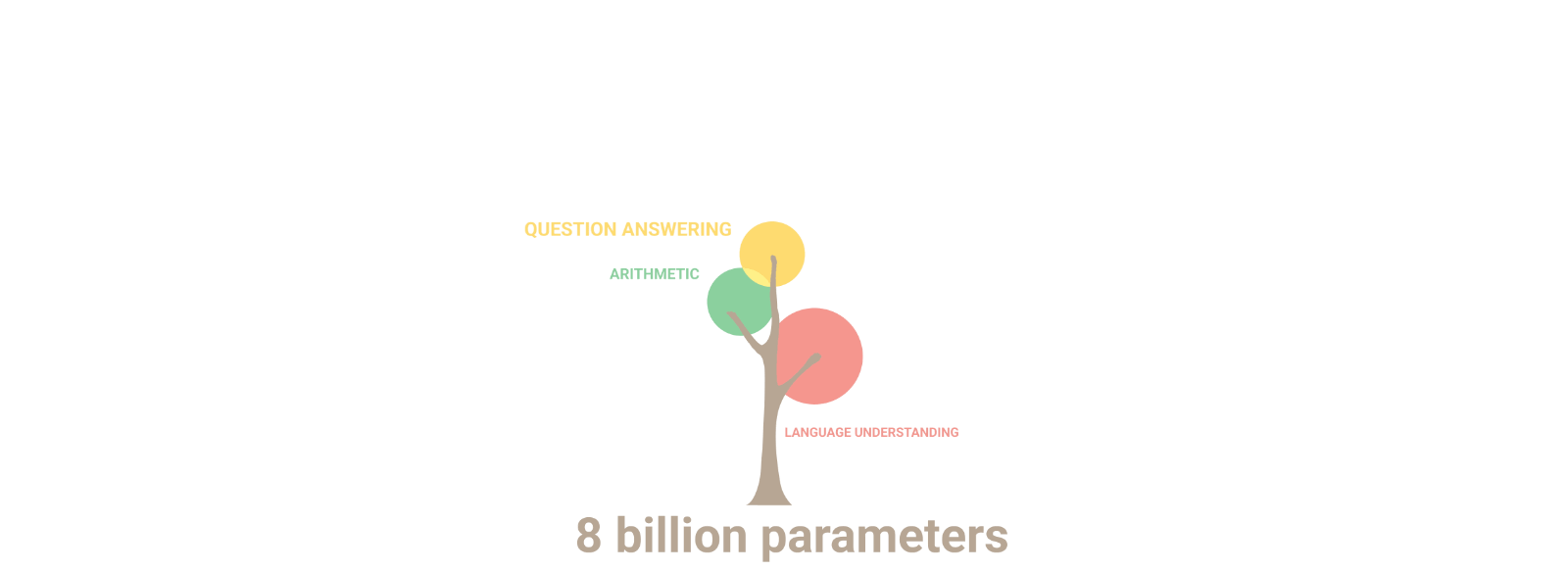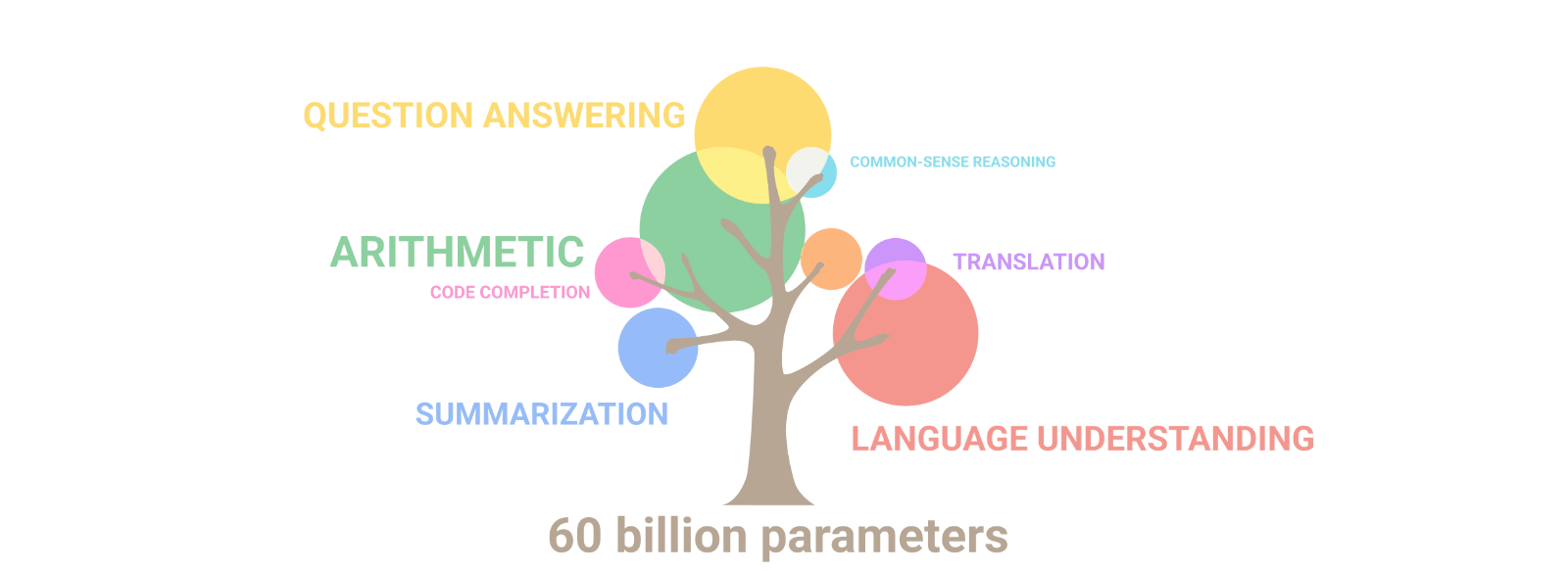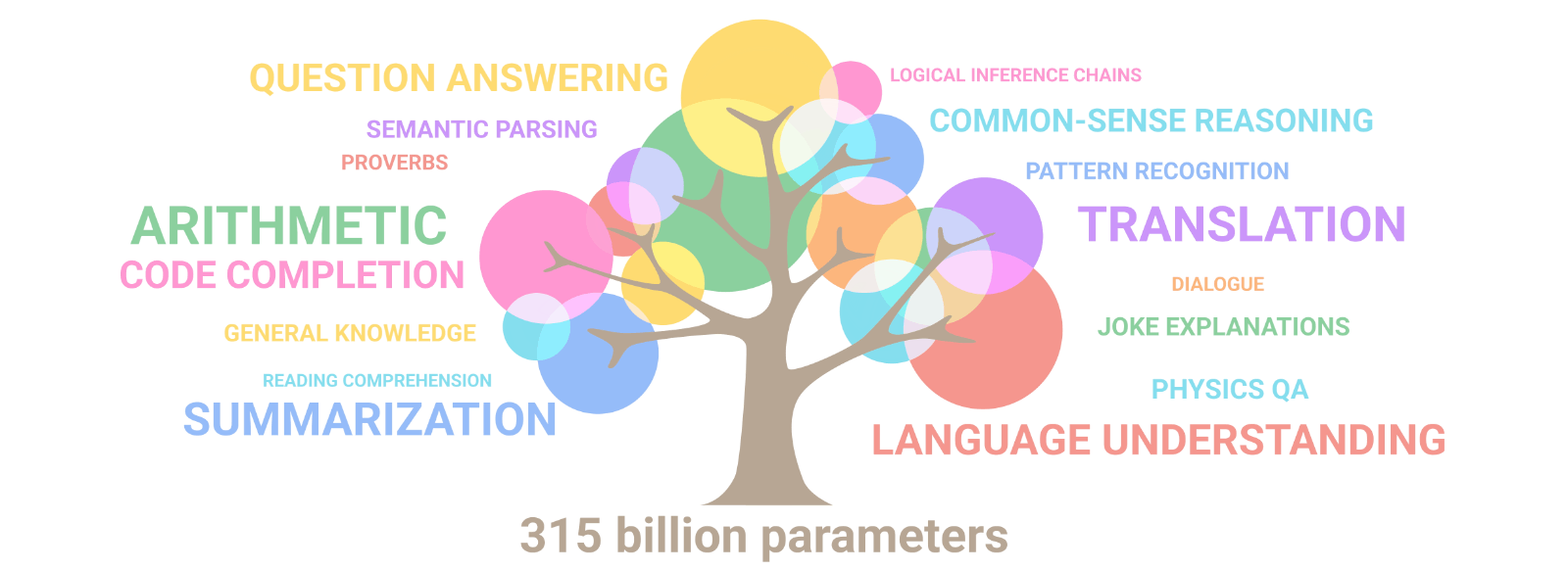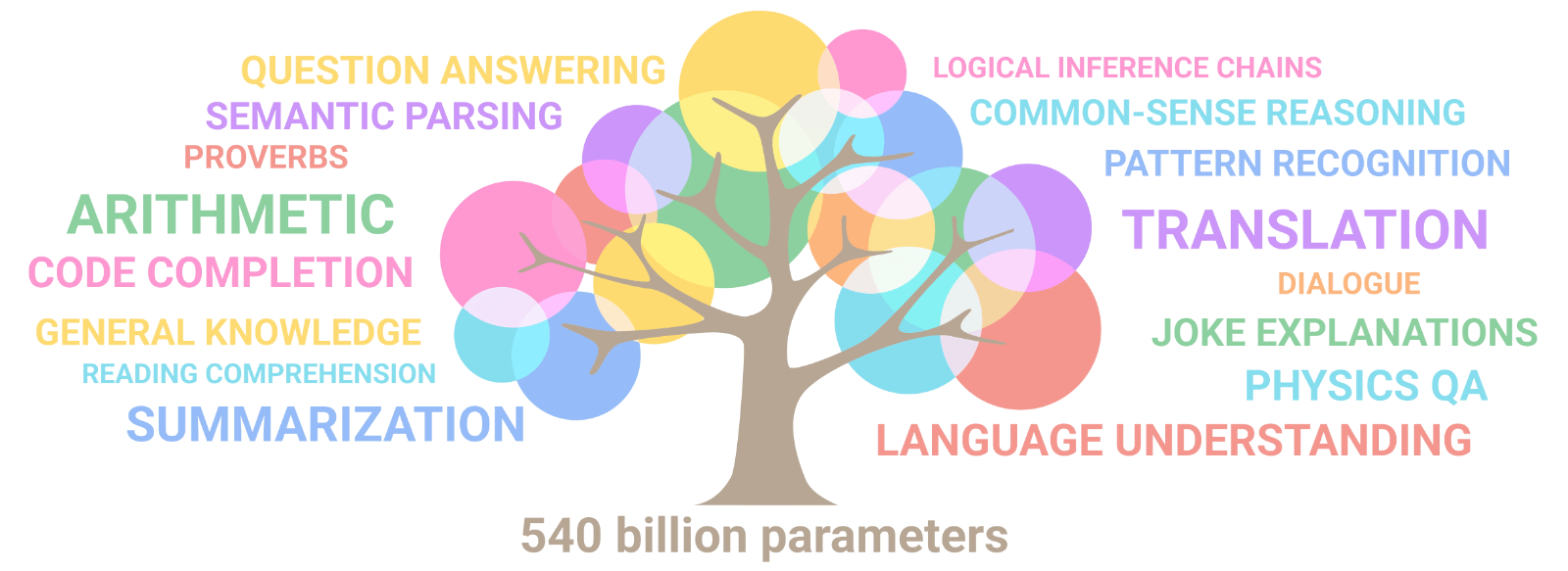
To understand the relationship between the number of parameters and the capabilities of a language model, let's take a look at how these models work. As the number of parameters in a GPT model increases, the model becomes more skillful at identifying subtle patterns and nuances in the input text, allowing it to generate more accurate and sophisticated outputs. This is because a larger number of parameters allows the model to capture more complex relationships between the input and output data.
However, simply adding more parameters to a model is not enough to improve its performance. The quality and diversity of the training data are also critical factors that influence the capabilities of a language model. The model needs to be trained on a large and diverse dataset that accurately represents the task or domain that it is intended to perform. If the dataset is biased or incomplete, the model may generate outputs that reflect these limitations.
Despite all of this, we can generally declare that increasing the number of parameters directly affects its capabilities. As language models become larger in size, they exhibit not only quantitative improvement but also novel qualitative capabilities.
The Road from Narrow AI to AGI
The three tasks that have to do with human-level understanding of natural language—reviewing a movie, holding a press conference, and translating speech—are the most difficult. Once we can take down these signs, we'll have Turing-level machines, and the era of strong AI will have started.
Ray Kurzweil
We have witnessed numerous use cases of narrow AI in the past few decades, with many surpassing human performance and setting new standards of living. As AI continues to advance, we can expect to see an increase in both the quantity and quality of narrow AI use cases. A network of specialized narrow AIs could potentially lead us into a new era of AI evolution.

By working together, narrow AI systems can build upon each other's strengths and compensate for each other's weaknesses and collectively form a more robust and sophisticated system. This network of specialized AI systems could enable us to accomplish complex tasks and solve problems that would be impossible for a single system to handle. However, the missing piece for achieving a general-purpose AI or AGI is the interoperability or connection between these systems.
Interoperability of narrow AI systems refers to the ability of different AI systems to work together seamlessly, allowing them to share information, collaborate on tasks, and collectively achieve a goal. This interoperability has the potential to lead to the development of AGI (Artificial General Intelligence) by creating a more comprehensive and integrated system.
For example, a speech recognition system could work together with a language translation system to accurately translate and interpret spoken language in real-time. In this way, the combined system would be more powerful and flexible than either system alone.
Interoperability can lead to a shared knowledge base between different AI systems, allowing them to collectively learn and improve over time. This shared knowledge could be used to train a more general AI system, capable of performing a wide range of tasks, rather than being limited to a specific domain. Interoperability of narrow AI systems has the potential to lead to AGI by creating a more integrated and comprehensive system that can learn and improve over time.
Theroy of Mind (ToM)
Theory of Mind is a psychological term that refers to the ability of an individual to understand and attribute mental states to oneself and others. It involves the ability to recognize that others have their own beliefs, desires, intentions, and emotions that may differ from one's own. This concept is an important aspect of social cognition and is thought to be a key component of social intelligence.
Theory of mind (ToM) is a key component of human social interactions and allows us to understand and impute mental states to others. It is also central to communication, empathy, self-consciousness, and morality. Until recently, ToM was thought to be a uniquely human ability. However, a study conducted on language models revealed that GPT-4 and its subsequent versions have shown impressive ToM-like abilities.
In a recent study 40 classic false-belief tasks were used to test the ToM of various language models. The results showed that language models published before 2020 were unable to solve ToM tasks. However, GPT-3, which was published in May 2020, solved approximately 40% of false-belief tasks. This performance was similar to that of a 3.5-year-old child. Its second version, “davinci-002”, which was published in January 2022, solved 70% of false-belief tasks, comparable to a six-year-old child. The next version, GPT-3.5, published in November 2022, solved 90% of false-belief tasks, which is similar to the performance of a seven-year-old child.
The latest model, GPT-4 published in March 2023 was able to solve nearly all the ToM tasks, with a score of 95%. These findings suggest that language models increasing language skills may have led to the emergence of ToM-like abilities. This development is significant since ToM was previously thought to be a uniquely human ability, highlighting the potential for artificial intelligence to possess human-like cognitive abilities.
Final Thoughts
While there is still a lot to be done before AI can truly be considered creative in the same sense as human beings, efforts to develop emergent abilities in AI are a promising step in that direction. As machines continue to become more complex and sophisticated, it is likely that we will see even more unexpected and innovative behaviors emerging, expanding the capabilities of AI and pushing the boundaries of what is possible.
Since these models have also shown the ability to spontaneously learn new skills, such as developing Theroy of Mind (ToM). Furthermore, models trained to predict the next word in a sentence have surprised their creators with their emergent reasoning and arithmetic skills, as well as their ability to translate between languages.
What's particularly interesting about these capabilities is that they were not engineered or anticipated by their creators. Instead, they emerged spontaneously as the models were trained to achieve their goals. This has led to a new era of AI research, where models are allowed to learn on their own, without being explicitly programmed for every task they need to perform. Maybe this would be the long-awaited “self-improving AI”? We may see it very soon given the current pace of progression.